
Attention is all you need - 论文阅读
Date:
论文: Transformer模型原理及部分代码介绍 论文地址:https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
一.概述
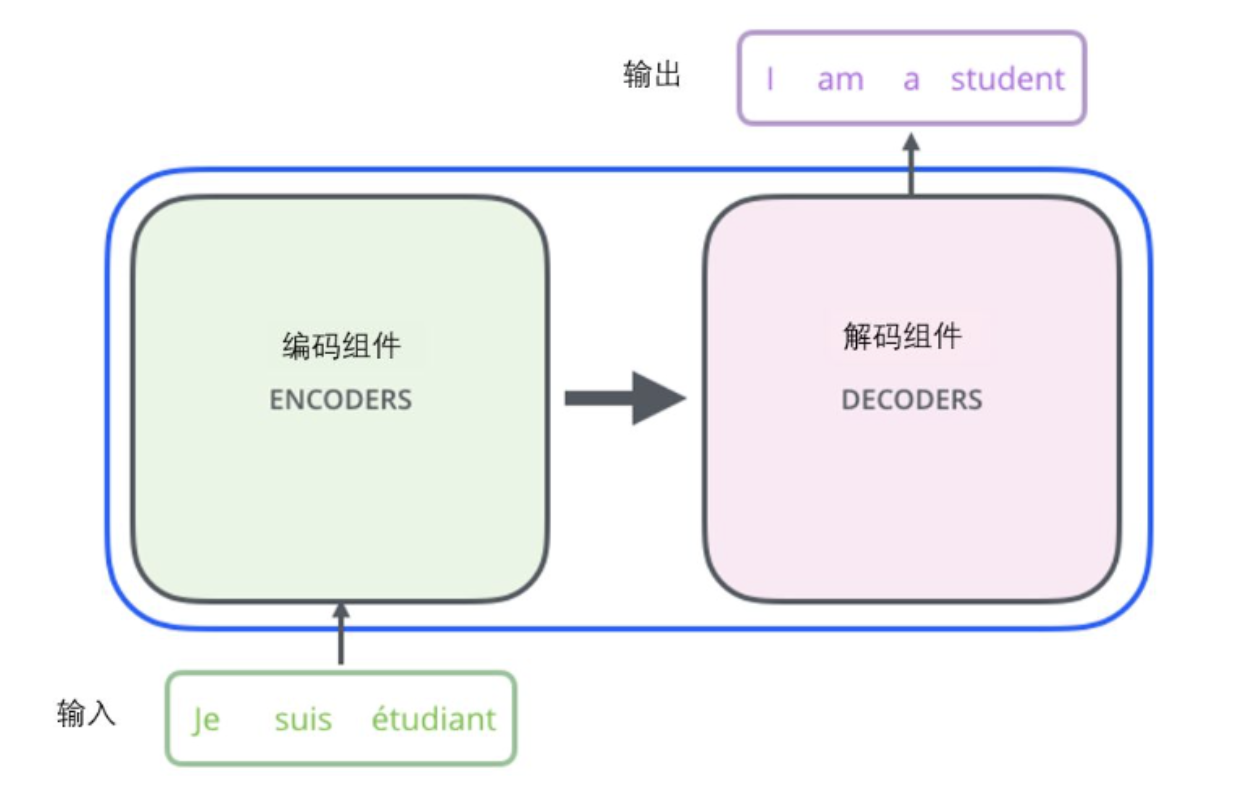
Transformer是一种仅使用attention机制、encoder-decoder架构的神经网络,最初应用于NLP领域的机器翻译,后逐渐在语音、CV、时间序列分析等多个领域成为主流深度模型。
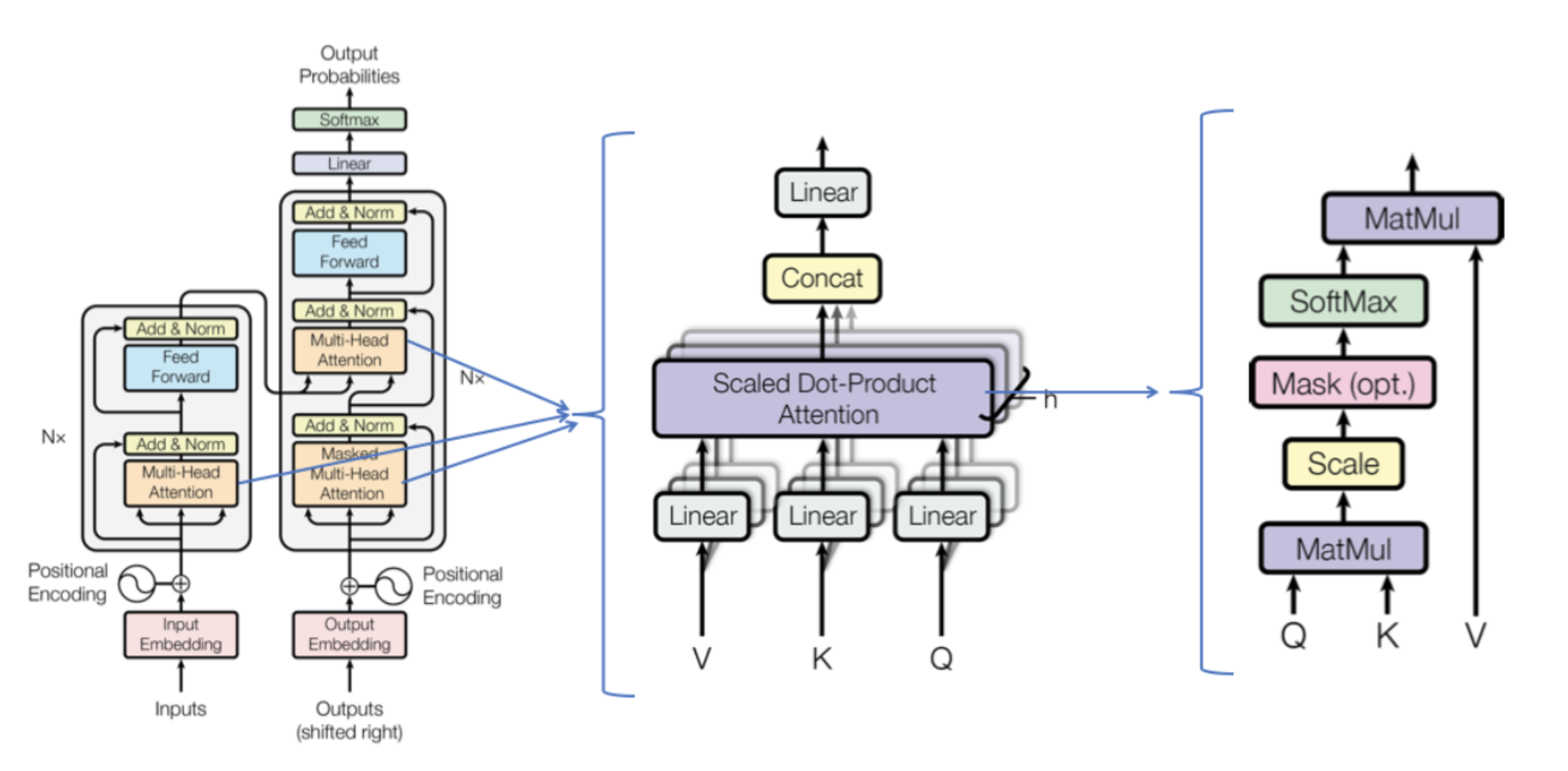
二. 模型结构
2.1 整体结构:Encoder-Decoder
Input:input Embedding + Position Encoding
Encoder:由N层自注意力块叠加而成,每个模块由多头自注意力模块 mutli-head self-attention、残差模块、Layer Normalization以及前馈神经网络组成。
Decoder:由N层自注意力块叠加而成,每个模块由掩码多头注意力模块 masked multi-head attention、残差模块、Layer Normalization、交叉注意力 cross attention以及前馈神经网络组成。
2.2 位置编码 Position Encoding
Attention机制不像CNN/RNN一样对输入顺序敏感,Attention是顺序不敏感的。为了使Attention能够感受到顺序的变化,Transformer引入了Position Encoding。
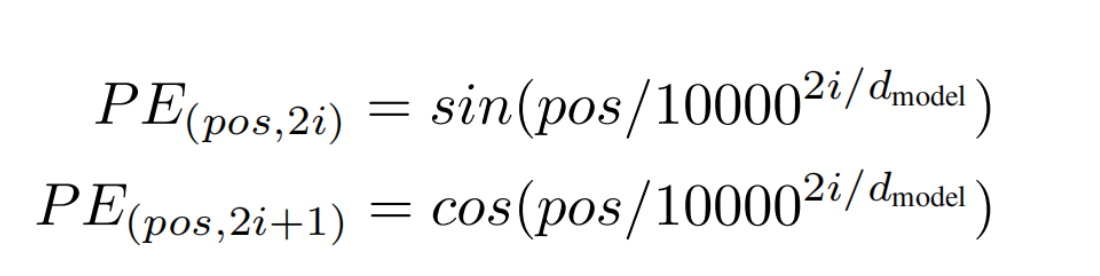
Position Encoding为什么是正余弦函数的形式?如何对位置进行编码?
最简单最能想到的方式:计数。0,1,2,3,4,5…..T-1,存在的问题:序列没有上界,如果 T=500 那最后一个字的编码就会比第一个位置的编码大太多,字嵌入合并以后会出现特征在数值上的倾斜和干扰字嵌入。
对计数归一化:序列有界了,但是仍有问题:不同序列长度的编码步长是不同的,比如“上海是直辖市”、“上海是中国的直辖市”两句话,“上”和“海”两个字在不同句子里的位置距离分别是1/6和1/9。编码位置信息的核心是相对位置关系,如果使用这种方式,长文本的相对次序关系就会被稀释
位置编码需要满足的条件:
- 顺序敏感:需要体现同一单词在不同位置的区别。
- 有界:需要有值域的范围限制。
- 编码步长相同:需要体现一定的先后次序,并且在一定范围内的编码差异不应该依赖于文本的长度,具有一定的不变性。
满足以上三个条件的函数:有界周期函数→三角函数。在不同维度使用不同周期的三角函数进行调控,周期最长为10000,可支持长序列输入,多个维度编码类似二进制编码,丰富了位置信息。
Position Encoding和Position Embedding的区别?
Position Encoding由于是三角函数,PE_t和PE_t+k、PE_t和PE_t-k的位置距离是一样的,因此,Position Encoding不具备方向性。
Position Encoding是参数固定的,由正余弦函数组成,无需学习;Position Embedding是需要参数学习的。因此Position Encoding有外推能力,可以输入比训练集所有序列更长的序列,Position Embedding如果输入更长的序列,找不到训练过的Embedding,因此不具备外推能力。
2.3 Transformer中的各种Attention
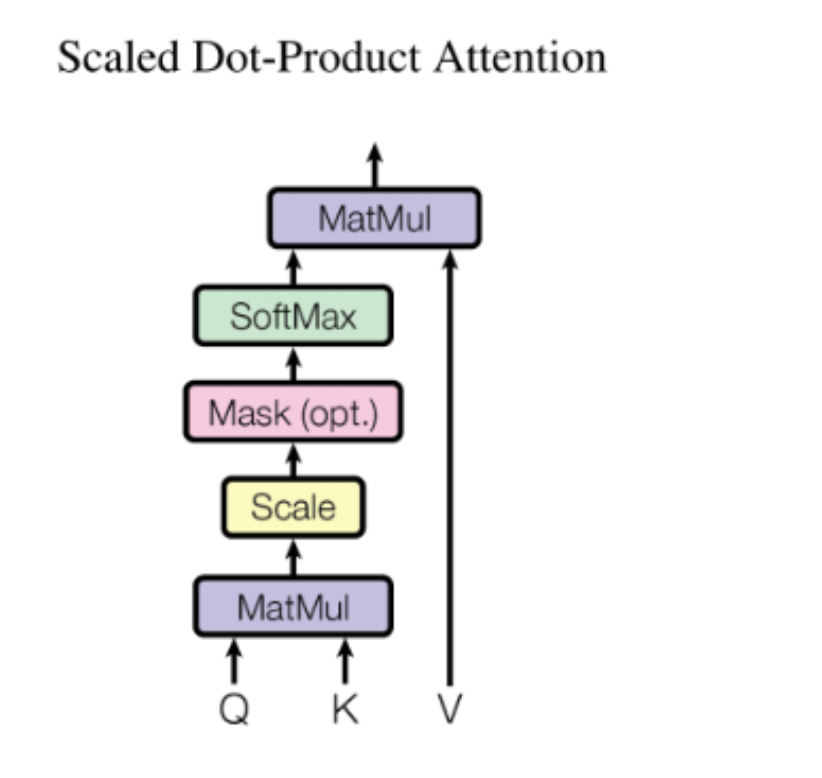
2.3.1 Scaled dot-product Attention
Attention机制可以描述为查表的过程,将各个时间步的输入映射为Query、Key、Value,在每个时间步计算当前时间步Query和所有时间步Key的相似度,根据相似度softmax之后的结果对所有时间步Value进行加权平均。
计算Attention方式:1. Dot-product Attention,求Q和K的内积
2. Additive Attention:score = MLP(Q|K)
Transformer中Dot-product Attention还需乘以缩放因子1/sqrt(d_k),为了避免softmax函数落入梯度饱和区.
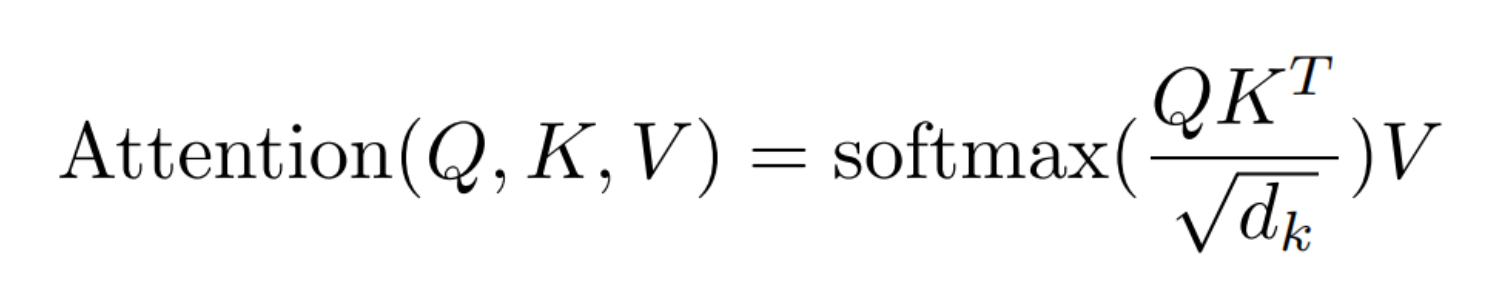
2.3.2 Multi-head Attention
Multi-head Attention将query、key、value映射到多个不同的子空间内,在多个子空间进行attention后,最后拼接起来
映射参数: 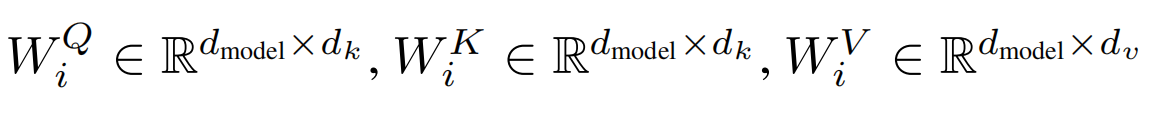
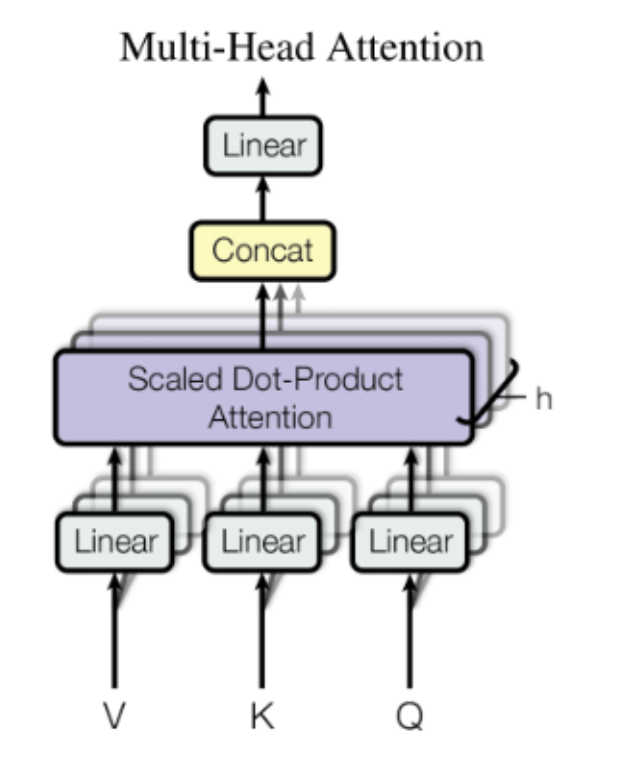

2.3.3 Masked Attention
在 Transformer中,解码器的self-Attention和编码器中的不同,解码器采用了Masked Attention。Masked Attention保证了解码器只能注意到当前位置之前的信息,保证了自回归性。
编码器是对已知输入序列进行编码,因此没有采用masked attention,可以注意到当前位置前后各个位置的信息。 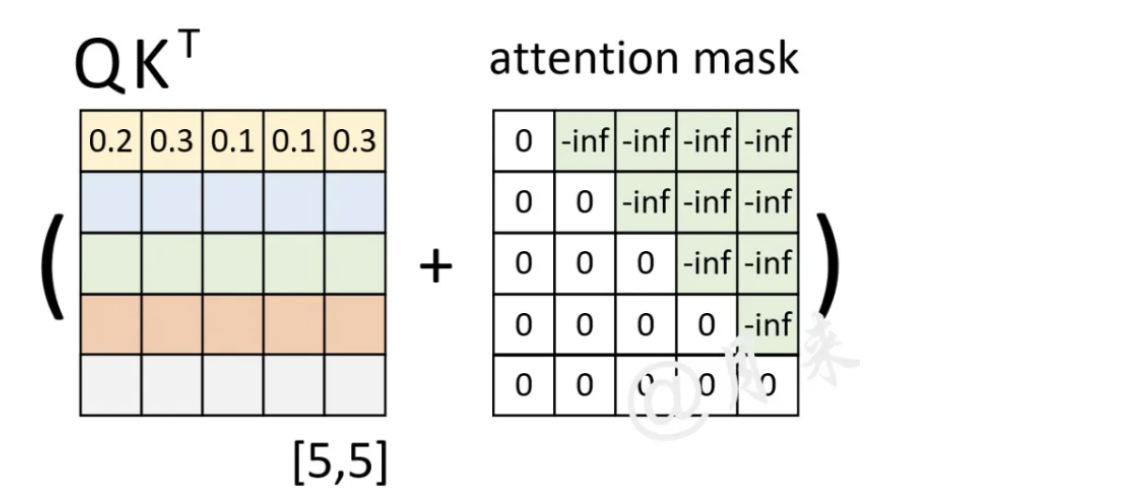
2.3.4 Cross Attention
Self-Attention输入是一个单一的嵌入序列,源序列;
Cross-Attention将两个相同维度的独立嵌入序列组合在一起,源序列和目标序列,目标序列用作查询输入,源序列作为键和值输入。 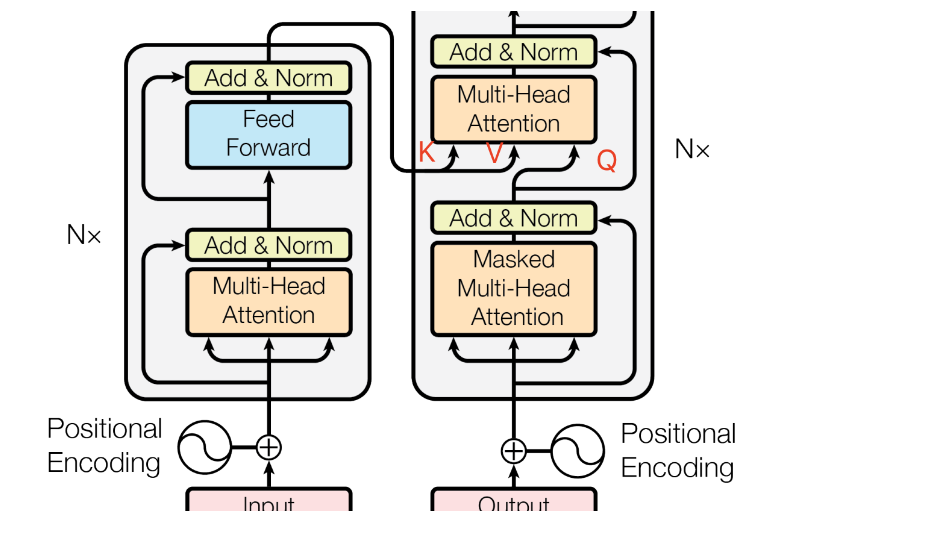
Transformer解码器从完整的输入序列开始,但解码序列为空。cross attention将信息从输入序列引入解码器,以便它可以预测下一个输出序列标记。然后,解码器将预测值添加到输出序列中,并重复此自回归过程
2.4 Position-wise Feed Forward Network
两层全连接层,独立应用在每个位置上,参数在每个位置共享。类似kernel大小为1的一维卷积。
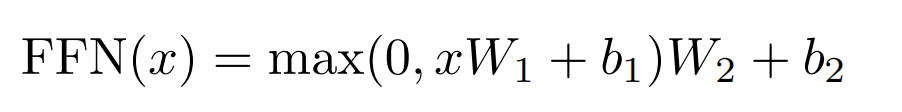
2.5 其他网络结构
残差块:跳跃连接,缓解梯度消失,防止网络退化 Layer Normalization:层归一化,使数据满足独立同分布,提高训练稳定性
四.应用
| Transformer编码器:Bert,Auto Encoder结构,双向attention,Masked Language Model,任务P(X_i | X_0, X_1…X_i-1, X_i+1, X_i+2….X_T)。缺货拟合由于销量缺失,天然形成mask,可以通过上下文进行填充,适合采用Encoder,比如SAITS模型。 |
| Transformer解码器:GPT,Auto Regression结构,单向attention,Language Model,任务:P(X_i | X_0, X_1…X_i-1) |